- Published on
GPU Basics
- Authors

- Name
- Garfield Zhu
- @_AlohaYo_
@Author: Garfield Zhu
Introduce GPU
Let's understand the GPU from the real hardware.
(AMD yes! But Nvidia demos only in this article. 🤣🤣🤣)
Architecture
Let's tear down a GTX 4080 GPU to see what's inside.
GTX 4080 - Full card

Other OEMs:


GTX 4080 - Board part

Open the panel

PCB panel

ROG Strix pcb:

Focus the core

Other views:
Other card

Move closer


Low-end cards

Now, let's focus on the core chip (Nvidia):
Exploded view (Tesla V100)

Abstract view

Fermi - with SM (Streaming Multiprocessor)

Streaming Multiprocessor from Cuda Cores

Kepler - open SM

Pascal - more SM

Volta - Tensor core


Ampere - RT core


⚖️ Compare with CPU
The CPU is suited to a wide variety of workloads, especially those for which latency or per-core performance are important. A powerful execution engine, the CPU focuses its smaller number of cores on individual tasks and on getting things done quickly. This makes it uniquely well equipped for jobs ranging from serial computing to running databases.
GPUs began as specialized ASICs developed to accelerate specific 3D rendering tasks. Over time, these fixed-function engines became more programmable and more flexible. While graphics and the increasingly lifelike visuals of today’s top games remain their principal function, GPUs have evolved to become more general-purpose parallel processors as well, handling a growing range of applications.
| CPU | GPU |
|---|---|
| General purpose | Specialized-purpose |
| Task parallelism | Data parallelism |
| A few heavyweight cores | Many lightweight cores |
| High memory size | High memory throughput |
| Many diverse instruction sets | A few highly optimized instruction sets |
| Explicit thread management | Threads are managed by hardware |

An example
CPU is like a workshop with one or serveral craftsmans. They are well-skilled and can do anythings if you give him a blueprint and enough time.
GPU is like a pipeline with many workers. They are poorly-educated but can do the same thing in parallel. Given simple and specific guide, they can do the job very fast.
🔖 Read GPU Spec
To better understand how the GPU performs, we should learn to read the spec of GPU of the core metrics.
We can find the centralized parameter specs of GPUs at the 3rd party: https://www.techpowerup.com/gpu-specs/
Or the details in the official website of the GPU manufacturer (NVidia, AMD, and Intel), e.g.
Cores
Similar as the CPU, the GPU has cores. The cores is used for parallel computing. Different from the CPU which has up-to 48 cores, the GPU has up-to 10,000 cores.
| Chip | Cores | Clock |
|---|---|---|
| Intel Core i9-13900K | 24 | 5.8 GHz (Turbo) |
| AMD Ryzen 9 7950X3D | 16 | 5.7 GHz (Boost) |
| AMD 7900XTX | 6144 | 2.5 GHz (Boost) |
| RTX 4070Ti | 7680 | 2.61 GHz (Boost) |
| RTX 4090 | 16384 | 2.52 GHz (Boost) |
| Tesla H100 | 14592 | 1.845 GHz (Boost) |
CUDA Cores (Nvidia)
Generally, The GPU cores are the shading units for rendering pipeline. But for Nvidia, it is called CUDA Cores with the strength of parallel computing with cores.
- They are highly parallel, meaning they can work on multiple tasks simultaneously.
- They have a high memory bandwidth, meaning they can quickly and easily access large amounts of data.
- They are designed specifically for algorithms that can be parallelized.

CUDA (Compute Unified Device Architecture) is the official name of GPGPU. Now it is used as the Nvidia core name and the most popular API on GPGPU.
Tensor Cores (Nvidia)
Essentially, Tensor cores are processing units that accelerate the process of matrix multiplication.
The computational complexity increases multifold as the size and dimensions of the matrix (tensor) go up. Machine Learning, Deep learning, Ray Tracing are tasks that involve an excessive amount of multiplication.

Ampere - Tensor core
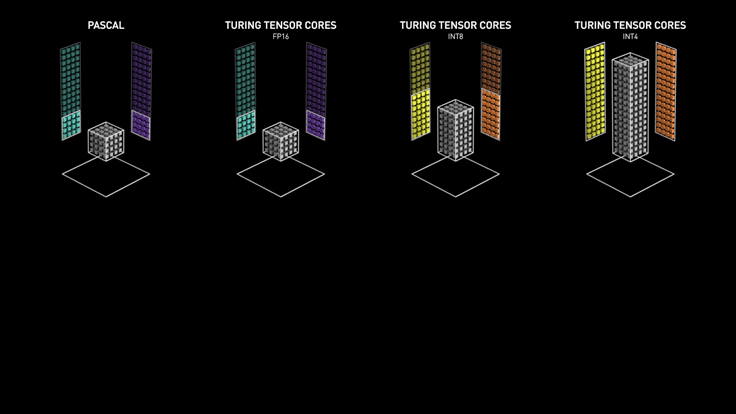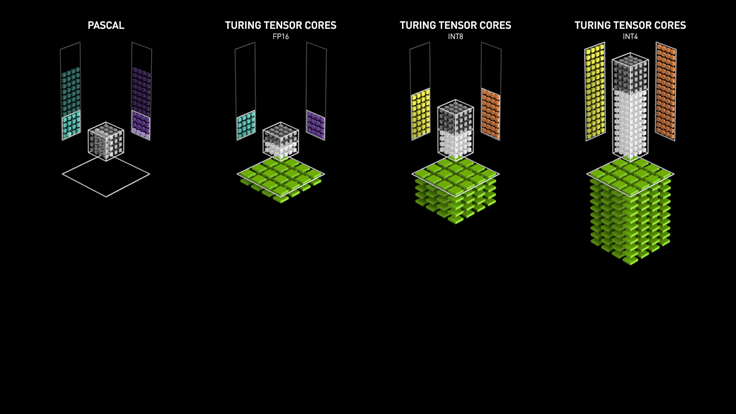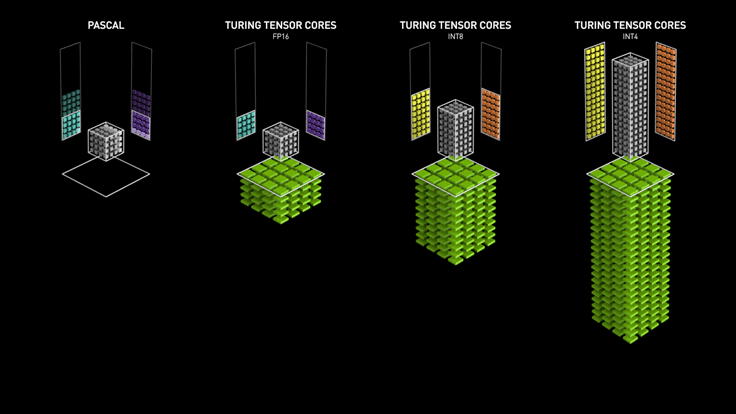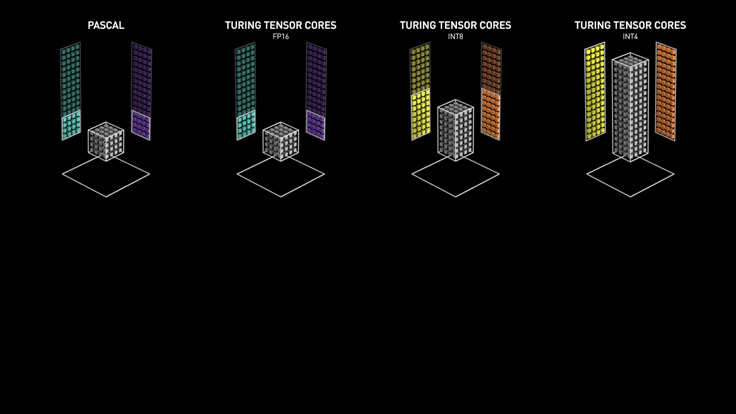
RT Cores
Known as "Ray Tracing Cores". It is a hardware implementation of the ray tracing technique.
Ray tracing calculation is a specific rendering pattern with ray related vector calcutions, refer to Ray Tracing notes

In short, RT cores add extra circuits to the more general purpose CUDA cores that can be included in the rendering pipeline when a ray-tracing calculation comes along.
Ray tracing Demo: NVIDIA Marbles at Night | RTX Demo
Bus, Clock & Memory
The specs of bus, clock & memory


Bus
The bus is the connection between the GPU and the motherboard. It is the data highway between the GPU and the CPU.
Bus type: PCIe 4.0, PCIe 5.0, etc.
See PCIe 4.0 vs 5.0Bus channel: x16, x8, x4, etc.
Bus width: 128-bit, 192-bit, 256-bit, 384-bit, etc.
Clock Speed
The clock speed is the speed of the GPU. (in MHz)
Just like the CPU. It contains the core clock speed and the memory clock speed.
Memory
The memory of GPU is called VRAM (Video RAM).
Memory type & size
- Type: GDDR5, GDDR6, GDDR6X, etc.
- Size: Nowaday, the mainstream is 8GB, 12GB, 16GB, 24GB etc.
Just like the RAM. The larger, the better. 🤣
The larger VRAM support:- [Graphics] Higher quality textures (4K, 8K, etc.)
- [Graphics] More complex geometry (higher poly count, tessellation, etc.)
- [Deep Learning] Larger dataset and batch sizes
- [Deep Learning] More complex and larger models
Memory Bus Width & BandWidth
- Bus Width: Or
Bit Width,Memory Interface Width. It is the number of bits that can be transferred simultaneously. - Bandwidth: The overall width of the memory bus. It is the product of the bus width and the clock speed.
- Formula:
Bandwidth = Bus Width * Clock Frequency * Architecture Multiplier - Unit: GB/s, e.g. 320 GB/s
- Formula:
- Bus Width: Or
Shader & TMU & ROP
For rendering pipeline:
GPU shadering unit for the shader programs on-GPU computation, which are the regular cores of GPU.
TMU stands for Texture Mapping Unit. It is a component of the video card or GPU that is responsible for mapping textures to polygons.
ROP stands for Render Output Unit. It is a component of the video card or GPU that is responsible for writing the final pixel data to the frame buffer.
TFLOPS
TFLOPS (teraFLOPS) is the tera (10^12) FLoating point Operations Per Second.
Generally, we say in 32-bit floating point.
GFLOPS, as we can guess, is the giga (10^9) of FLOPS. It was used in years ago and now we are in TFLOPS era.
Cross-platform's battle of TFLOPS in their graphics core:
| Platform | TFLOPS |
|---|---|
| PS5 | 10.28 |
| XBOX Series X | 12.00 |
| Nintendo Switch | 0.4 / 0.5 (Docked) |
| Apple A17 Pro | 2.15 |
| Apple M2 Ultra (76 core) | 27.2 |
| Intel UHD Graphics 770 | 0.794 |
| Intel Iris Xe Graphics G7 96RUs | 1.690 |
| Intel Arc A770 | 19.66 |
| AMD Radeon RX 7800 XT | 37.32 |
| AMD Radeon RX 7900 XTX | 61.42 |
| GeForce RTX 2080 Ti | 13.45 |
| GeForce RTX 3090 | 35.58 |
| GeForce RTX 4070 Ti | 40.09 |
| GeForce RTX 4090 | 82.58 |
| Tesla H100 | 67 |
Example
Now, let's read a spec of RTX 4090:

How GPU runs
CPU runs code

Traditional GPU runs code

GPGPU
In general purpose GPU architecture, Nvidia leverages the CUDA cores (typically 128 cores) to constructs SM (Streaming Multiprocessor) to run the code.

GTX 980 (2014 - Maxwell)


Program with GPU
OpenGL & GLSL
OpenGL (Open Graphics Library) is a cross-language, cross-platform API for rendering 2D and 3D vector graphics.
GLSL (OpenGL Shading Language), is a high-level shading language based on the C programming language.
WebGL & WebGPU
WebGL (Web Graphics Library) is a JavaScript API for rendering interactive 2D and 3D graphics within any compatible web browser without the use of plug-ins.
CUDA
CUDA is a parallel computing platform and programming model developed by Nvidia for general computing on its own GPUs (graphics processing units).
Different from the OpenGL, CUDA is a general-purpose parallel computing platform and programming model. OpenGL focuses on the graphic rendering, while CUDA is for parallel computing. (e.g. Deep Learning, Crypto Mining)

C sample:
// CUDA C
__global__ void myKernel() {
printf("Hello world\n");
}
int main(int argc, char const *argv[]) {
myKernel<<<4,2>>>();
return 0;
}
Python sample:
# CUDA Python by numba
from numba import cuda
def cpu_print(N):
for i in range(0, N):
print(i)
@cuda.jit
def gpu_print(N):
idx = cuda.threadIdx.x + cuda.blockIdx.x * cuda.blockDim.x
if (idx < N):
print(idx)
def main():
print("gpu print:")
gpu_print[2, 4](8)
cuda.synchronize()
print("cpu print:")
cpu_print(8)
if __name__ == "__main__":
main()